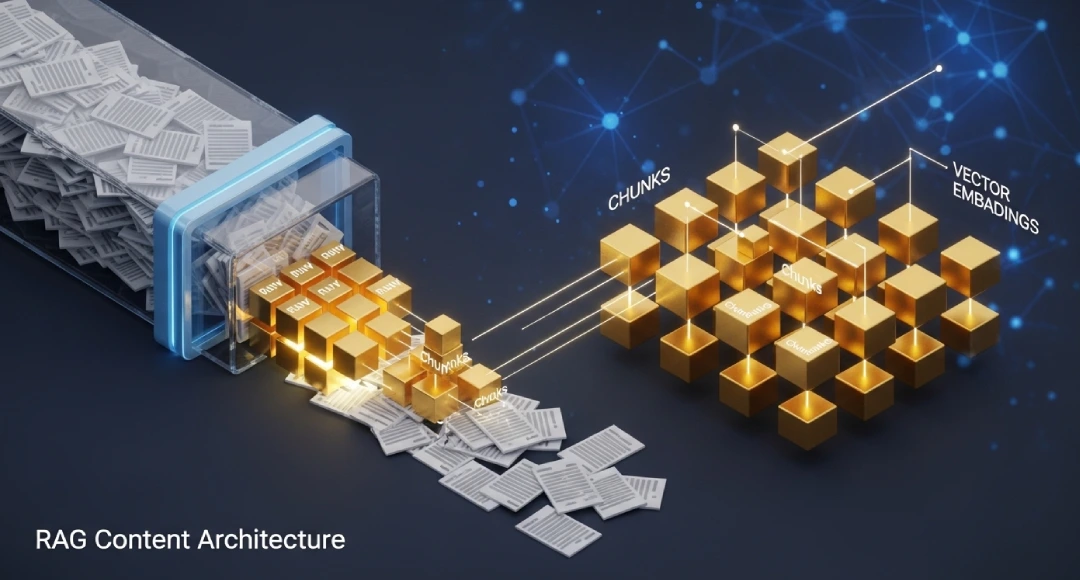
RAG-Ready (RAG Uyumlu) İçerik Mimarisi; dijital içeriklerin sadece insanlar tarafından okunması için değil, Büyük Dil Modelleri (LLM) ve Vektörel Veritabanları tarafından “anlamlandırılabilir”, “parçalanabilir” (chunkable) ve “geri çağrılabilir” (retrievable) veri blokları halinde tasarlanması disiplinidir. Bu yaklaşım, SearchGPT, Perplexity ve Google Gemini gibi yapay zeka tabanlı arama motorlarında görünürlük elde etmenin tek teknik yoludur.
RAG (Retrieval-Augmented Generation) Nedir?
RAG (Erişim Destekli Üretim); Büyük Dil Modellerinin (LLM) eğitim verisindeki kısıtlamaları aşmak için, harici ve güvenilir veri kaynaklarından (web siteleri, veritabanları) gerçek zamanlı bilgi çekerek yanıt üretmesini sağlayan hibrit bir yapay zeka mimarisidir. Basitçe; yapay zekanın ezberden konuşmak yerine, “önündeki kitaba bakarak” cevap vermesidir.
LLM’ler İçeriği Nasıl Okur?
Dijital yayıncılık dünyası, yirmi yıldır “Anahtar Kelime” (Keyword) egemenliği altındaydı. Bir içeriğin içinde “SEO” kelimesi kaç kez geçerse, Google’ın o sayfayı bulma ihtimali o kadar artardı. Ancak Üretken Yapay Zeka (Generative AI) devrimi, bu kuralları tamamen geçersiz kıldı.
Yapay zeka modelleri (LLM’ler), kelimeleri saymaz; onları vektörlere (sayısal koordinatlara) dönüştürür.
Bugün, SearchGPT veya Google Gemini bir kullanıcı sorusuna yanıt verirken, klasik web taraması (crawling) yerine RAG (Retrieval-Augmented Generation) teknolojisini kullanır. RAG sistemleri, milyarlarca veri parçası arasından soruyla en alakalı “bağlamı” (context) bulur ve bunu modele sunar.
Sorun şudur: Eğer içeriğiniz RAG sistemlerinin “okuma mantığına” uygun kurgulanmadıysa, dünyanın en kaliteli makalesini yazsanız bile, yapay zeka sizi “göremez”. Bu makale, içeriğinizi yapay zeka botlarının diline (Embeddings) nasıl çevireceğinizi ve RAG-Ready bir mimariyi nasıl kuracağınızı anlatır.
RAG Sistemi Nasıl Çalışır? (Teknik Bakış)
İçeriğinizi optimize etmeden önce, karşı tarafın nasıl düşündüğünü anlamalısınız. RAG süreci üç temel aşamadan oluşur ve içerik stratejiniz bu aşamalara göre şekillenmelidir:
- Parçalama (Chunking): Yapay zeka, 3000 kelimelik bir makaleyi tek lokmada yutmaz. Metni, anlamlı küçük parçalara (genellikle 256 veya 512 token uzunluğunda “chunk”lara) böler.
- Vektörize Etme (Embedding): Her parçayı, çok boyutlu bir uzayda sayısal bir vektöre dönüştürür. (Örneğin: “Elma” ve “Armut” kelimelerinin vektörleri birbirine yakındır).
- Geri Çağırma (Retrieval): Kullanıcı bir soru sorduğunda, sistem veritabanındaki en yakın vektörü (sizin içeriğinizin bir parçasını) bulur ve cevabı oluşturmak için kullanır.
Önemli Bilgi: Eğer paragraflarınız çok uzunsa, karmaşıksa veya konu bütünlüğü yoksa; “Chunking” aşamasında metniniz parçalanır ve anlamını yitirir. Anlamını yitiren parça, vektör uzayında kaybolur.
RAG Uyumlu İçerik İçin 4 Altın Kural
İçeriğinizin “Vektör Kalitesini” (Embedding Quality) artırmak ve LLM’ler tarafından seçilme ihtimalini (Retrieval Probability) maksimize etmek için aşağıdaki mimari kuralları uygulamanız zorunludur.
1. “Chunking” Dostu Paragraf Yapısı
Yapay zeka modellerinin “Context Window” (Bağlam Penceresi) sınırlıdır. Bu nedenle, metni bir yapboz gibi tasarlamalısınız. Her parça, bütünden koparıldığında bile tek başına bir anlam ifade etmelidir.
- Eski SEO: “Giriş, gelişme, sonuç” bağlamında birbirine bağımlı, upuzun paragraflar.
- RAG Stratejisi: Her biri tek bir fikri (Micro-Idea) işleyen, 100-150 kelimelik, bağımsız (self-contained) bloklar.
- Uygulama: Bir paragrafta “RAG Mimarisi”ni anlatıyorsanız, aynı paragraf içinde “Google Reklamları”na geçiş yapmayın. Konu değiştiği an, yeni bir başlık (H3) veya yeni bir paragraf açın. Bu, yapay zekanın o parçayı doğru etiketlemesini sağlar.
2. Varlık Yoğunluğu (Entity Density) ve İsimlendirme
LLM’lerin en büyük düşmanı “Zamirler”dir (O, Bu, Şu, Onlar).
Neden? Çünkü bir RAG sistemi, makalenizin ortasından bir paragrafı cımbızla çekip aldığında, o paragrafta geçen “Bu sistem harikadır” cümlesindeki “Bu sistem”in ne olduğunu anlayamaz. Bağlam kaybolur.
- Yanlış: “O, pazarlamada devrim yarattı. Şirketler onu kullanarak maliyetleri düşürdü.” (Burada “O”nun Yapay Zeka mı, Blockchain mi olduğu belirsizdir).
- Doğru: “Üretken Yapay Zeka, pazarlamada devrim yarattı. Şirketler Generative AI kullanarak maliyetleri düşürdü.”
Kural: Kritik anahtar kelimeleri (Entities) paragraf içinde tekrar etmekten korkmayın. Bu, “Keyword Stuffing” (Kelime yığma) değildir; bu “Contextual Anchoring” (Bağlamsal Çapalama) işlemidir.
3. Hiyerarşik Metadata Olarak Başlıklar
H2 ve H3 başlıklarınız, sadece okuyucunun gözünü dinlendirmek için değildir. Bu başlıklar, RAG sistemi için birer “Dosya Etiketi”dir.
Yapay zeka, içeriği parçalarken başlıkları da meta veri olarak kaydeder. Başlıklarınız ne kadar açıklayıcı ve soru odaklı olursa, eşleşme o kadar kesin olur.
- Kötü Başlık: “Neden Önemli?” (Neyin önemi?)
- İyi Başlık: “RAG Mimarisi Neden Dijital Pazarlama İçin Önemli?” (Tam Bağlam)
4. Yapılandırılmış Veri: LLM’in Ana Dili
Büyük Dil Modelleri, düz metin (unstructured data) yerine yapılandırılmış veriyi (structured data) işlemeyi tercih eder. Neden? Çünkü yapılandırılmış veride “Halüsinasyon” (yanlış bilgi üretme) riski daha düşüktür.
İçeriğinizde aşağıdaki HTML yapılarını kullanmak, RAG skorunuzu doğrudan artırır:
- Tanım Listeleri (
<dl>,<dt>,<dd>): Kavramları net tanımlamak için. - Tablolar (
<table>): Verileri karşılaştırmak için. - Sıralı Listeler (
<ol>): Süreçleri adım adım anlatmak için.
RAG Mimarisi ile Geleneksel SEO Farkı
Bu yeni dönemi daha iyi anlamak için, klasik SEO ile RAG odaklı içerik üretimini karşılaştıralım:
| Özellik | Geleneksel SEO (Keyword Search) | RAG Mimarisi (Vector Search) |
| Odak Noktası | Anahtar Kelime Hacmi | Anlamsal Yakınlık (Semantic Proximity) |
| Metin Yapısı | Uzun, akıcı makaleler | Modüler, parçalanabilir bilgi blokları |
| Dil Kullanımı | Okuyucuyu sitede tutmaya yönelik | Bilgiyi en kısa sürede vermeye yönelik |
| Başarı Metriği | Tıklama Oranı (CTR) | Alıntılanma ve Referans Gösterilme |
| Teknik Altyapı | Meta Tagler, Backlinkler | Embedding Kalitesi, Varlık İlişkileri |
Sektörler İçin Uygulama Örnekleri
RAG uyumlu içerik stratejisi, her sektörde farklı uygulanabilir. İşte üç farklı dikeyle ilgili somut senaryolar:
1. E-Ticaret ve Ürün Açıklamaları
Bir kullanıcı “Ofis için en ergonomik sandalye hangisi?” diye sorduğunda, RAG sistemi binlerce ürün açıklamasını tarar.
Eski Yöntem: “Bu sandalye çok rahattır.”
RAG-Ready: “Herman Miller Aeron sandalye, Pellicle süspansiyon teknolojisi sayesinde bel desteği (lumbar support) sağlar ve ofis ergonomisini %40 artırır.” (Marka, Teknoloji ve Fayda net olarak belirtilmiştir).
2. Finans ve Bankacılık
Kullanıcı sorusu: “Kredi kartı faizleri nasıl hesaplanır?”
RAG-Ready: Formülü düz metin olarak yazmak yerine, adım adım bir liste (<ol>) veya hesaplama tablosu kullanın. Yapay zeka bu yapıyı alıp doğrudan cevaba dönüştürür.
3. Sağlık ve Tıp (YMYL)
Sağlık içeriklerinde RAG sistemleri, kaynağın otoritesine (E-E-A-T) bakar. Her tıbbi iddianın yanına parantez içinde kaynak belirtmek (örn: “Dünya Sağlık Örgütü, 2024 Raporu”), vektörün güven skorunu artırır.
Geleceğin İçeriği
İçerik pazarlamasında “RAG-Ready” dönemine geçiş, bir tercih değil zorunluluktur. Yapay zeka asistanlarının (Copilots) internetin ana arayüzü haline geldiği bir dünyada, içeriğinizin “vektörize edilebilir” olması, var olmanız demektir.
Stratejinizi şu üç adıma indirgeyerek hemen uygulamaya başlayın:
- Metinlerinizi bağımsız, anlamlı bloklara (Chunks) bölün.
- Zamir kullanımını azaltın, varlık isimlendirmelerini (Entities) artırın.
- Bilgiyi düz yazı yerine tablolar ve listelerle sunun.
Unutmayın, geleceğin SEO uzmanları “kelime avcısı” değil, “bilgi mimarı” olacaktır.
8 Şubat 2026
Yorum yapılmamış
Yazar: Gökhan AKSOY